 |
 |
|
ジャストシステムの高度な日本語形態素解析(*)エンジンを組み込んだメールフィルターです。
迷惑メールとして振り分けたメールの特徴を学習して、次回以降は類似する特徴を持つメールを、自動的に迷惑メールとして判別します。
単純に文字列で比較する従来のフィルターとは異なり、めんどうな条件設定をしなくても、毎回パターンを変えて送りつけられるしつこい迷惑メールを、効率的に排除することができます。
*形態素解析について詳しく知りたい方はこちら |
|
 |
|
 |
 |
|
 |
| ◆学習を重ねるごとに判定精度がアップ。 |
|
|
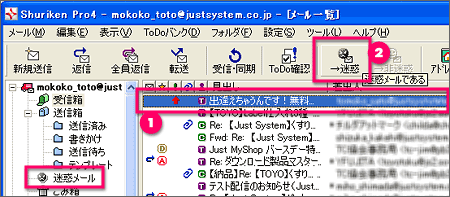
学習&排除の操作はたった2ステップ(*)。
 メールを選んで、 メールを選んで、 迷惑メールと判定するだけで、学習と排除が完了します。 迷惑メールと判定するだけで、学習と排除が完了します。
*迷惑メール判定と同時にブラックリストへ自動登録する設定の場合 |
|
 |
|
| *従来のShurikenユーザーの方が、ツールバーのカスタマイズを行っている場合は、「→迷惑」「→非迷惑」ボタンは表示されません。[設定
- ツールボックス設定]で、これらをツールバーに表示させることができます。 |
|
|
| ◆迷惑メール専用フォルダを搭載 |
|
|
| 「ゴミ箱」に捨てたメールと自動排除されたメールとを区別できて、安心です。 |
|
|
| ◆パソコンに負荷をかけず、受信も高速 |
|
|
| メモリに常駐するタイプのフィルターとは異なり、必要なときだけ動作するので、パソコンに負荷をかけず、受信も高速です。 |
|
|
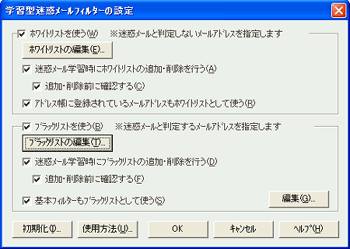
| ◆ホワイトリスト(許可リスト)で、非迷惑メールの誤判定を防止 |
|
|
| アドレス帳のデータを、ホワイトリストに利用することもできます。 |
|
|
| ◆ブラックリスト(禁止リスト)で、確実に迷惑メールを排除 |
|
|
特徴が少なく、迷惑メールとして判定されにくい迷惑メールも、ブラックリストを使えば、確実に排除できます。
また、従来の「Shuriken Pro4」に搭載されていた基本フィルターは、学習型迷惑メールフィルターのブラックリストとして、そのままご利用いただけます。
*差出人や見出しとの文字列比較により迷惑メールを判定する「基本フィルター」も搭載しています。ご利用の目的に合わせて、使用する迷惑メールフィルターを選択できます。 |
|
| 【形態素解析とは?】 |
形態素解析とは、文章を意味のある最小単位に分割し、文章に使われている語句の識別や品詞などを解析する技術です。
今回の「学習型迷惑メールフィルター」では、弊社独自の高度な形態素解析エンジンを組み込んで、迷惑メール判定や学習を行っており、以下のような特長を持ちます。
|
| ■ |
微妙に表記が異なる単語も、同一と見なすことができます。
例えば「バイオリン」と「ヴァイオリン」。
この2つが指しているものの意味は同じで、人はこの2つを同一視します。
しかし、表記が異なるためプログラムでは異なるものと扱われます。
今回の「学習型迷惑メールフィルター」では、単語の統制を掛けることにより、この2つをどちらも「バイオリン」としてプログラム内で扱うことができます。
この他にも名詞であれば、
・「ユーザー」 「ユーザ」 →「ユーザー」
・「慶応」 「慶應」 →「慶応」
動詞であれば語幹を見て、
・「動く」 「動かない」 →「動」
という風に同一視し、同じ表記に統制して使用するものがいくつもあります。
この処理により、表記を微妙に変化させた単語でも、統制後の単語がすでに迷惑メールとして学習されていれば、同じ単語として処理し、迷惑メールとして判定されます。
|
| ■ |
判定に用いる単語の品詞を限定することで、特徴を捉えやすくなります。
・「は」 「に」 「を」 「へ」等の助詞
・「ある」 「この」等の連体詞
・「さらには」 「かつ」等の接続詞
・サ変本体(「さ」 「し」 「す」 「する」 「すれ」 「せよ」)
これらのように、迷惑メール/非迷惑メールにかかわらず、日本語の文章ならどちらにも入っているような品詞は、迷惑メールの特徴としてとらえることはできません。
そこで、このように特徴として捉えることができない品詞は、今回の「学習型迷惑メールフィルター」では対象にしないようになっています。
たとえば、「本日は晴天なり。」ですと、
|
| |
| 本日 |
は |
晴天 |
なり |
。 |
| [名詞] |
[助詞] |
[名詞] |
[助動詞] |
[記号] |
|
|
| |
となって、Shurikenでは「本日」「晴天」のみが判定に使用されます。 |
|
|
|
|
|