 |
|||||||||||||||||||||||
| ジャストシステムの高度な日本語形態素解析(*)エンジンを組み込んだメールフィルターです。 めんどうな条件設定は不要。 ドラッグ&ドロップなどで「迷惑メールフォルダ」に振り分けたメールの特徴を学習し、次回以降は自動的に排除します。 単純に文字列で比較するフィルターとは異なり、類似する特徴を持つ迷惑メールも賢く判別します。見出しなどのヘッダ情報だけでなく、メール本文や添付ファイルの内容も合わせて総合的に判断するので、「お久しぶりです」などの一般的な見出しを付けた巧妙な迷惑メールにもだまされません。 *形態素解析について詳しく知りたい方はこちら |
|||||||||||||||||||||||
 |
|||||||||||||||||||||||
| ◆学習を重ねるごとに判定精度がアップ | |||||||||||||||||||||||
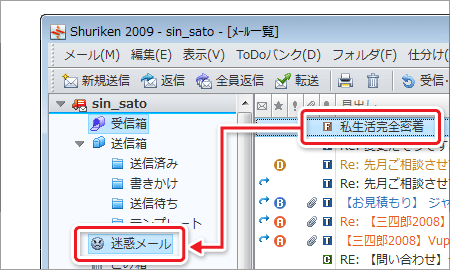
| 学習&排除の操作はかんたん。 メールを選んで、迷惑メールフォルダへドラッグ&ドロップするだけでOKです。 |
|||||||||||||||||||||||
 |
|||||||||||||||||||||||
| *従来のShurikenユーザーの方が、ツールバーのカスタマイズを行っている場合は、「→迷惑」「→非迷惑」ボタンは表示されません。[設定 - ツールボックス設定]で、これらをツールバーに表示させることができます。 | |||||||||||||||||||||||
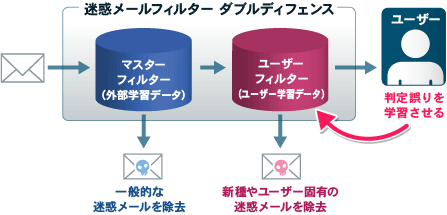
| ◆2つのフィルターが迷惑メールを逃さない | |||||||||||||||||||||||
| 「迷惑メールフィルター ダブルディフェンス」を搭載。 学習初期でも、一般的な迷惑メールなら事前に学習済みのマスターフィルターが除去。マスターフィルターが取りこぼした新種の迷惑メールや判断の難しいメールも、ユーザーフィルターに学習させることで、どんどん精度が上がっていきます。 |
|||||||||||||||||||||||
 |
|||||||||||||||||||||||
| マスターフィルターに使う外部学習データは「Shuriken 2009」に搭載しますが、管理者やユーザーが作成することもできます。 | |||||||||||||||||||||||
| ◆パソコンに負荷をかけず、受信も高速 | |||||||||||||||||||||||
| メモリに常駐するタイプのフィルターとは異なり、必要なときだけ動作するので、パソコンに負荷をかけず、受信も高速です。 | |||||||||||||||||||||||
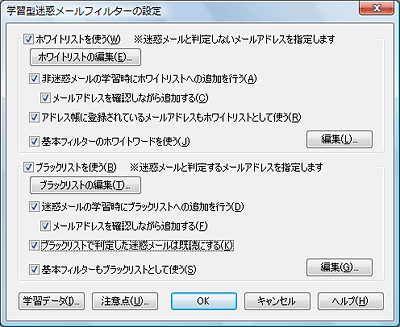
| ◆ホワイトリスト(許可リスト)で、非迷惑メールの誤判定を防止 | |||||||||||||||||||||||
| アドレス帳のデータを、ホワイトリストに利用することもできます。 | |||||||||||||||||||||||
| ◆ブラックリスト(禁止リスト)で、確実に迷惑メールを排除 | |||||||||||||||||||||||
| 特徴が少なく、迷惑メールとして判定されにくい迷惑メールも、ブラックリストを使えば、確実に排除できます *差出人や見出しとの文字列比較により迷惑メールを判定する「基本フィルター」も搭載しています。ご利用の目的に合わせて、使用する迷惑メールフィルターを選択できます。 |
|||||||||||||||||||||||
| ◆安心&快適のための機能を満載! | |||||||||||||||||||||||
| ■迷惑メール専用フォルダが便利!「ゴミ箱」に捨てたメールと区別できて安心 ■迷惑メールフォルダ内メールの自動削除も可能 ■「迷惑メールは着信報告を行わない」設定で、さらに快適に ■学習データを複数PCで利用。インポート/エクスポート機能を搭載 ■空メールや外国語のメールを迷惑メールに指定可能 ■「Kaspersky Internet Security」のアンチスパム機能と連携 |
|||||||||||||||||||||||
| ◆「Shuriken 2009」では、さらにここが機能アップ!<UP> | |||||||||||||||||||||||
基本フィルターに、学習型フィルターのホワイトリストとしても使用可能な「ホワイトワード」の機能を追加しました。任意の文字列をホワイトワードとして登録しておくことで、この文字列が含まれたメールは必ず「迷惑メールではない」と判定させることができます。
|
|||||||||||||||||||||||
| 学習型フィルターのブラックリストや基本フィルターによって迷惑メールと判定されたメールを「既読」にするオプションをご用意。これにより、「確認済み、または、確認しなくても間違いなく迷惑メール(既読メール)」と、「誤判定でないか念のため確認した方がよいメール(未読メール)」を区別できるようになりました。 |
|||||||||||||||||||||||
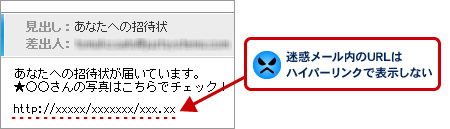
| 迷惑メールフォルダのメールについては、ビューアでURLやメールアドレスをハイパーリンクで表示しないようにしました。これにより、迷惑メールに含まれるURLをうっかりクリックして、フィッシング詐欺サイト等の危険なページにアクセスしてしまう被害を未然に防ぎます。 | |||||||||||||||||||||||
 |
|||||||||||||||||||||||
|
|||||||||||||||||||||||